Poster is on display.
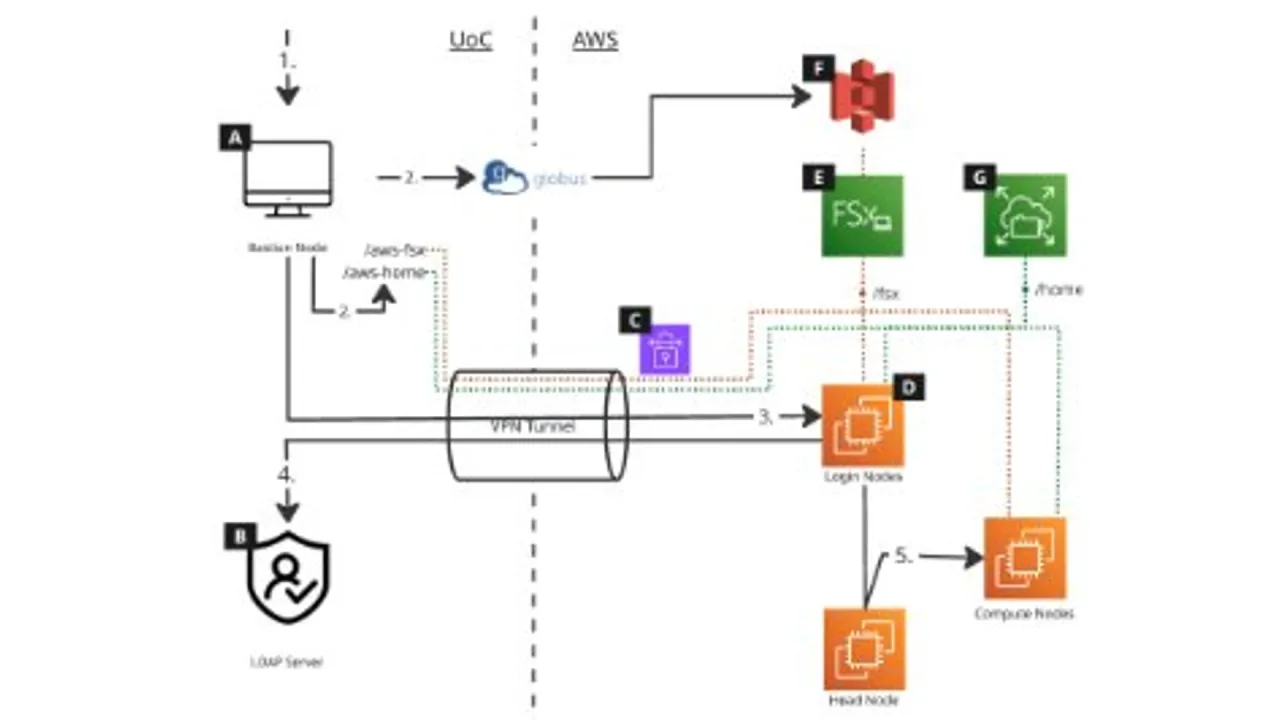
On-premise HPC services are increasingly constrained by power, space, and procurement timelines, while users require access to a broader and rapidly evolving range of compute architectures. This project addresses the challenge of extending an existing production HPC service into the cloud in a managed and controlled manner. We present a managed cloud extension for HPC and AI services at the University of Cambridge that enables scalable and burstable access to additional compute capacity. The platform is designed to be HPC-first, allowing users to access cloud resources using familiar mechanisms such as SSH, consistent permissions, and Slurm scheduling, without the need to learn cloud-specific tools. This minimises application portability effort while maintaining a consistent user experience. The system provides rapid access to diverse hardware for short-term workloads and application benchmarking, enabling evidence-based evaluation of new architectures prior to on-premise procurement. A governed and repeatable operational model ensures cost control and mitigates the risks associated with unmanaged cloud usage. Beyond capacity expansion, this work establishes a foundation for improved service continuity and future cloud-based resilience.