Understanding Buffer Allocation and Data Transfer Mechanisms on AMD MI300A APUs
Wednesday, June 24, 2026 3:45 PM to 5:15 PM · 1 hr. 30 min. (Europe/Berlin)
Foyer D-G - 2nd Floor
Research Poster
Heterogeneous System ArchitecturesMemory Technologies and HierarchiesPerformance MeasurementRuntime Systems for HPC
Information
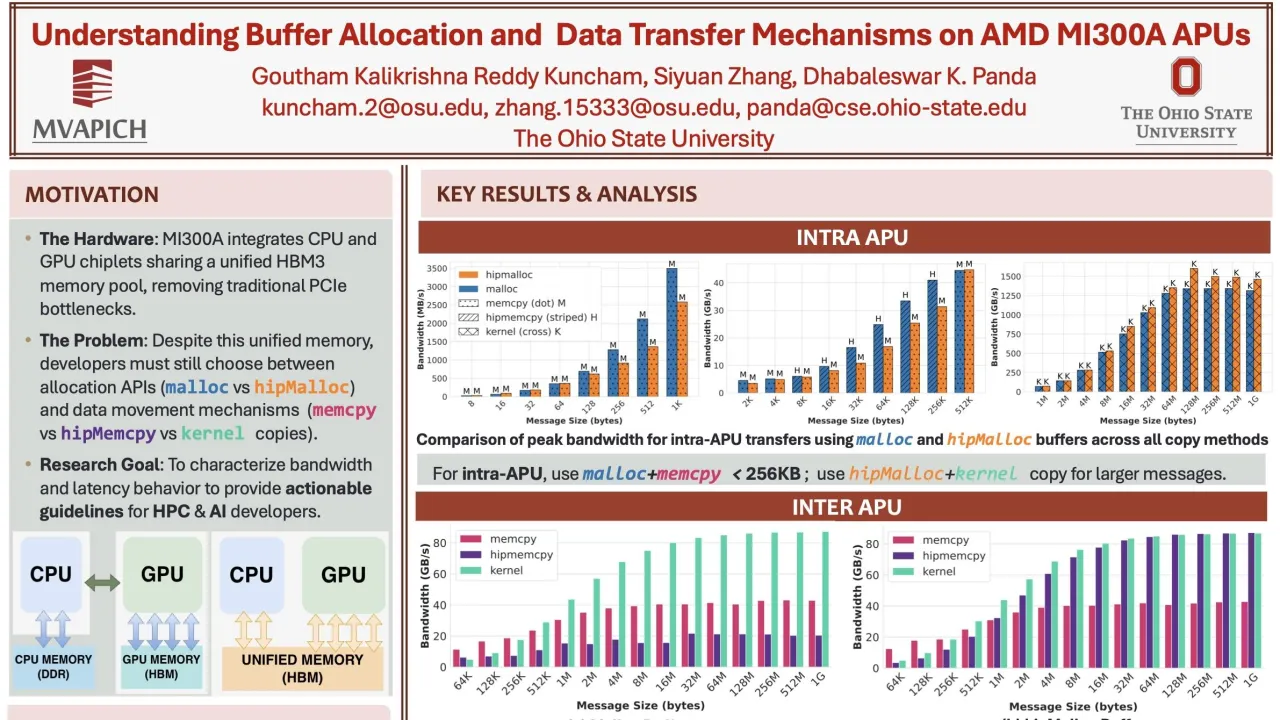
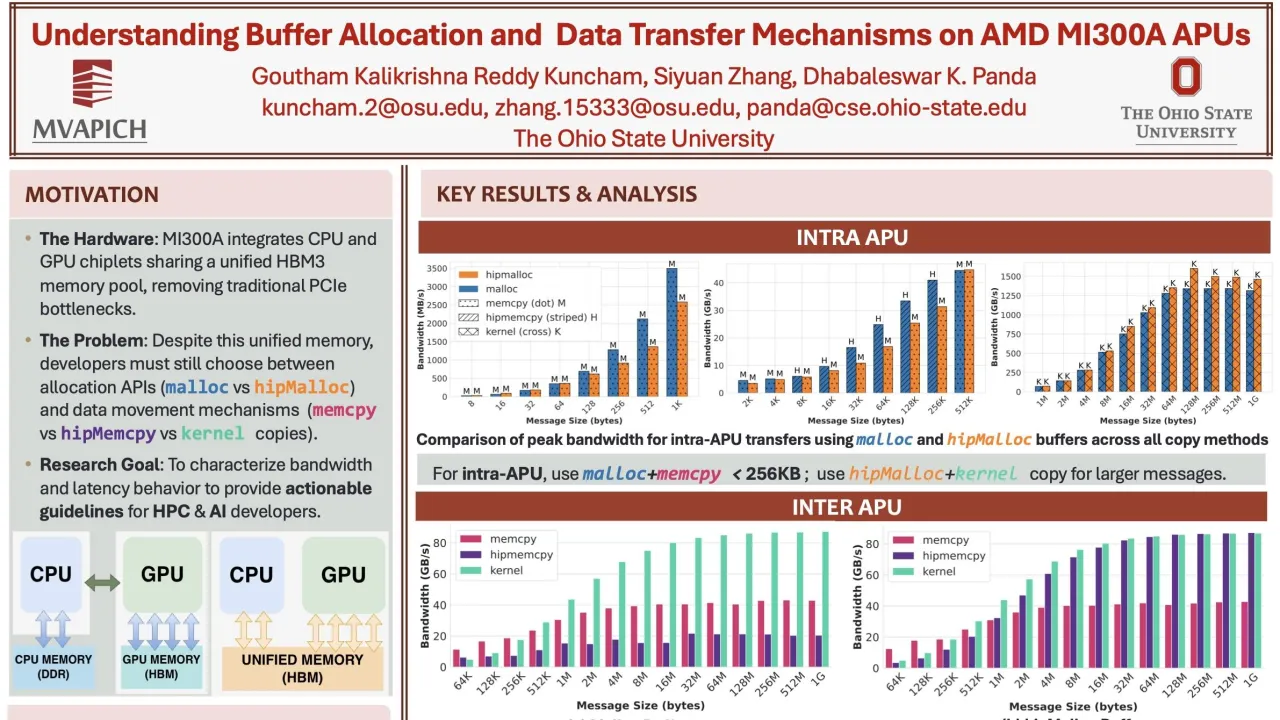
Poster is on display and will be presented at the poster pitch session. The emergence of unified memory architectures represents a major advancement in heterogeneous computing. The AMD MI300A pioneers this as the first production-scale Accelerated Processing Unit (APU) featuring a unified HBM3 memory pool accessible by both CPU and GPU compute units, offering the potential to bypass longstanding CPU-to-GPU data copy bottlenecks. However, this architectural innovation also raises important research questions about how memory allocation and data transfer strategies impact overall application performance. In this paper, we conduct a comprehensive performance evaluation of memory allocation and data transfer methods on the AMD MI300A APU. We systematically evaluate the bandwidth and latency characteristics of different memory allocation methods (Malloc and hipMalloc) and data copy methods (CPU-based memcpy and GPU-based hipMemcpy and custom kernel copies). Our experiments span a wide range of message sizes and cover intra-APU, inter-APU, and inter-node scenarios. Our analysis yields empirical insights to guide efficient data movement on unified-memory architectures and provides actionable guidelines for MPI library developers aiming to design efficient communication runtimes tailored to the MI300A APU architecture. Building on these insights, we develop and demonstrate a memory-aware adaptive prototype scheme that selects data transfer methods based on message size and buffer type. This prototype achieves practical performance improvements in collective communication, realizing up to 60% improvement for Alltoall operations and up to 80% improvement for Allreduce, along with up to 27% gains in real-world application workloads.Contributors: