Optimizing Legacy Fortran Code: A Case Study Using MONARCH
Wednesday, June 24, 2026 3:45 PM to 5:15 PM · 1 hr. 30 min. (Europe/Berlin)
Foyer D-G - 2nd Floor
Research Poster
Earth, Climate and Weather ModelingOptimizing for Energy and PerformanceParallel Numerical AlgorithmsPerformance and Resource ModelingPerformance Measurement
Information
Poster is on display and will be presented at the poster pitch session.
The Multiscale Online Nonhydrostatic AtmospheRe CHemistry (MONARCH) model is a high-resolution chemical weather prediction system designed to simulate atmospheric composition, air quality, and pollutant concentrations. MONARCH simulates multi-scale physics with very high computational demands, as it integrates complex chemical transport and aerosol dynamics across large domains. Like many legacy scientific codes, MONARCH contains a large base of older, poorly maintained code, which can limit performance and prevent efficient use of modern high-performance computing (HPC) resources.
In contemporary scientific software development, there is often a strong focus on novel algorithmic techniques or publications, sometimes at the expense of traditional code engineering methods. While innovative approaches can provide important scientific insights, low-level performance optimization of legacy codes remains critical to achieve reliable, efficient simulations at scale. These traditional methods are essential not only to improve time-to-solution but also to reduce energy consumption, computing costs, and overall HPC resource usage, which are increasingly important considerations in modern scientific computing.
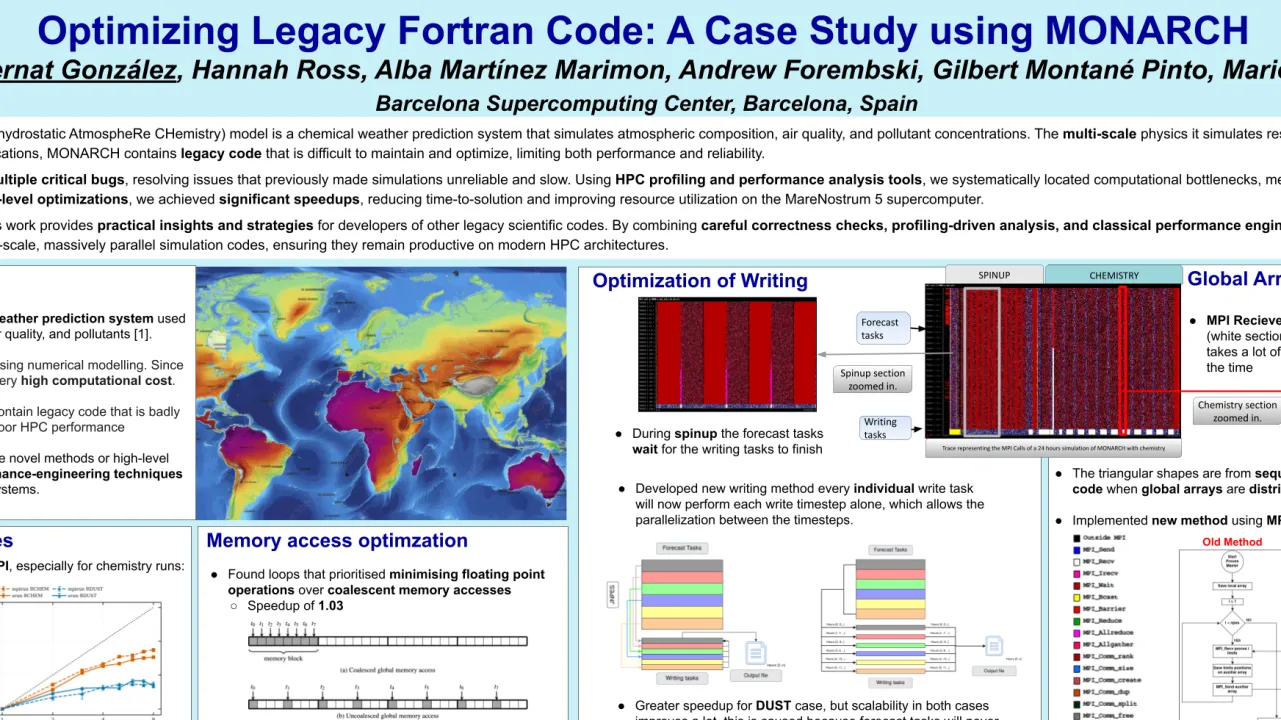
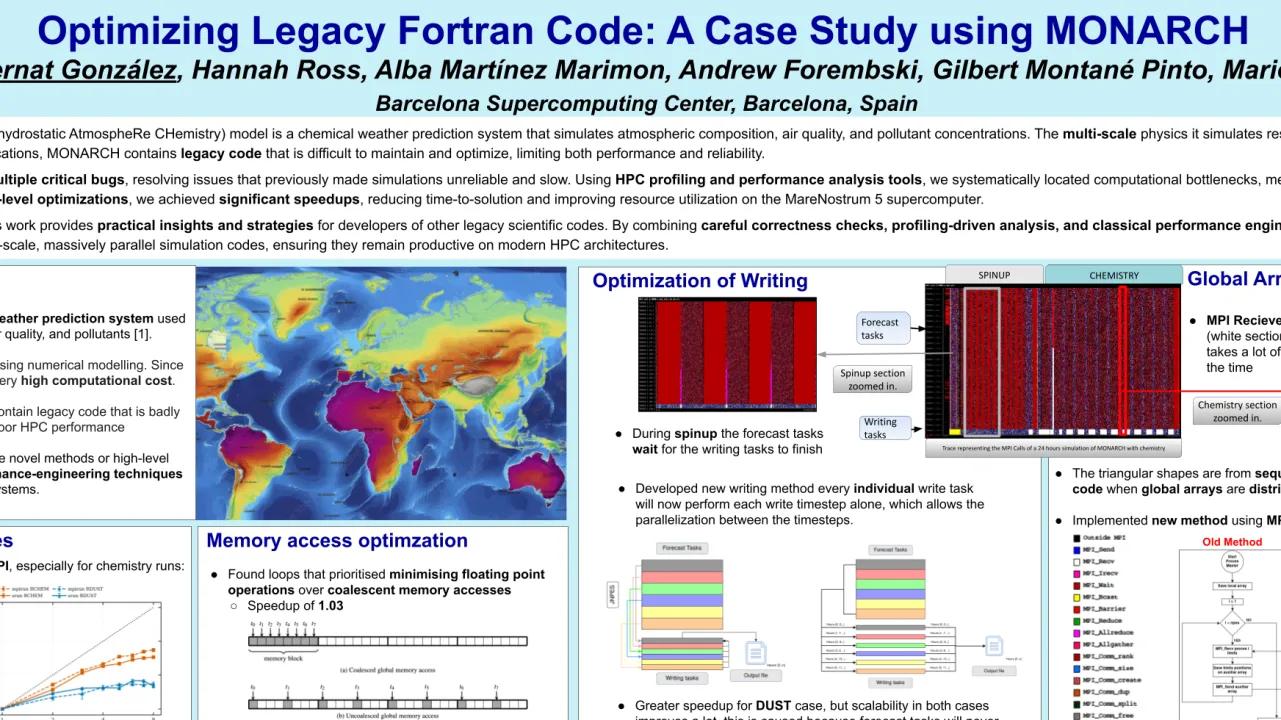
In this work, we systematically applied performance engineering techniques to MONARCH, addressing both correctness and computational efficiency. We identified and fixed critical bugs, which had previously caused unreliable results and prevented large-scale production runs. These bug fixes also enabled the use of more aggressive compiler optimization flags (switching from -O2 to -O3), unlocking additional performance potential. For simulation outputs, we implemented parallel NetCDF writing, enabling multiple processes to write data concurrently, rather than sequentially. To further increase science output, we implemented offline nesting, which allows multiple child domain simulations to be run concurrently for a single parent domain. This approach improves overall throughput and better utilizes HPC resources, as it overlaps computations across domains without serial bottlenecks.
Using in-house profiling tools, Extrae and Paraver, which allowed us to precisely locate computational bottlenecks in both CPU-bound and memory-bound sections of the code. We investigated the behavior of the writing tasks (MPI ranks assigned to write simulation outputs while other ranks continue with the next time-step) and by changing the way these tasks are group achieved speedup of up to 2.0× for writing simulation outputs. We analyzed the distribution of global arrays used in MONARCH. The original implementation relied on point-to-point MPI communications, which scaled poorly for large domain sizes and high process counts. By switching to collective MPI communication, we achieved a 1.22× speedup, improving both scalability and resource efficiency.
Our combined efforts demonstrate that classical performance optimization techniques remain essential for legacy scientific codes, particularly in the context of HPC resource management. By carefully combining bug fixes, profiling-guided optimizations, parallel I/O improvements, collective communication strategies, and offline nesting, we significantly improved the robustness, performance, and scalability of MONARCH on the MareNostrum supercomputer. These improvements not only enhance the performance of MONARCH itself but also provide a practical roadmap for researchers working on similar legacy simulation codes.
Contributors:
The Multiscale Online Nonhydrostatic AtmospheRe CHemistry (MONARCH) model is a high-resolution chemical weather prediction system designed to simulate atmospheric composition, air quality, and pollutant concentrations. MONARCH simulates multi-scale physics with very high computational demands, as it integrates complex chemical transport and aerosol dynamics across large domains. Like many legacy scientific codes, MONARCH contains a large base of older, poorly maintained code, which can limit performance and prevent efficient use of modern high-performance computing (HPC) resources.
In contemporary scientific software development, there is often a strong focus on novel algorithmic techniques or publications, sometimes at the expense of traditional code engineering methods. While innovative approaches can provide important scientific insights, low-level performance optimization of legacy codes remains critical to achieve reliable, efficient simulations at scale. These traditional methods are essential not only to improve time-to-solution but also to reduce energy consumption, computing costs, and overall HPC resource usage, which are increasingly important considerations in modern scientific computing.
In this work, we systematically applied performance engineering techniques to MONARCH, addressing both correctness and computational efficiency. We identified and fixed critical bugs, which had previously caused unreliable results and prevented large-scale production runs. These bug fixes also enabled the use of more aggressive compiler optimization flags (switching from -O2 to -O3), unlocking additional performance potential. For simulation outputs, we implemented parallel NetCDF writing, enabling multiple processes to write data concurrently, rather than sequentially. To further increase science output, we implemented offline nesting, which allows multiple child domain simulations to be run concurrently for a single parent domain. This approach improves overall throughput and better utilizes HPC resources, as it overlaps computations across domains without serial bottlenecks.
Using in-house profiling tools, Extrae and Paraver, which allowed us to precisely locate computational bottlenecks in both CPU-bound and memory-bound sections of the code. We investigated the behavior of the writing tasks (MPI ranks assigned to write simulation outputs while other ranks continue with the next time-step) and by changing the way these tasks are group achieved speedup of up to 2.0× for writing simulation outputs. We analyzed the distribution of global arrays used in MONARCH. The original implementation relied on point-to-point MPI communications, which scaled poorly for large domain sizes and high process counts. By switching to collective MPI communication, we achieved a 1.22× speedup, improving both scalability and resource efficiency.
Our combined efforts demonstrate that classical performance optimization techniques remain essential for legacy scientific codes, particularly in the context of HPC resource management. By carefully combining bug fixes, profiling-guided optimizations, parallel I/O improvements, collective communication strategies, and offline nesting, we significantly improved the robustness, performance, and scalability of MONARCH on the MareNostrum supercomputer. These improvements not only enhance the performance of MONARCH itself but also provide a practical roadmap for researchers working on similar legacy simulation codes.
Contributors:
Format
on-demandon-site

