A Framework for Developing Next-Generation HPC Schedulers
Wednesday, June 24, 2026 3:45 PM to 5:15 PM · 1 hr. 30 min. (Europe/Berlin)
Foyer D-G - 2nd Floor
Research Poster
Performance Tools and SimulatorsResource Management and Scheduling
Information
Poster is on display and will be presented at the poster pitch session.
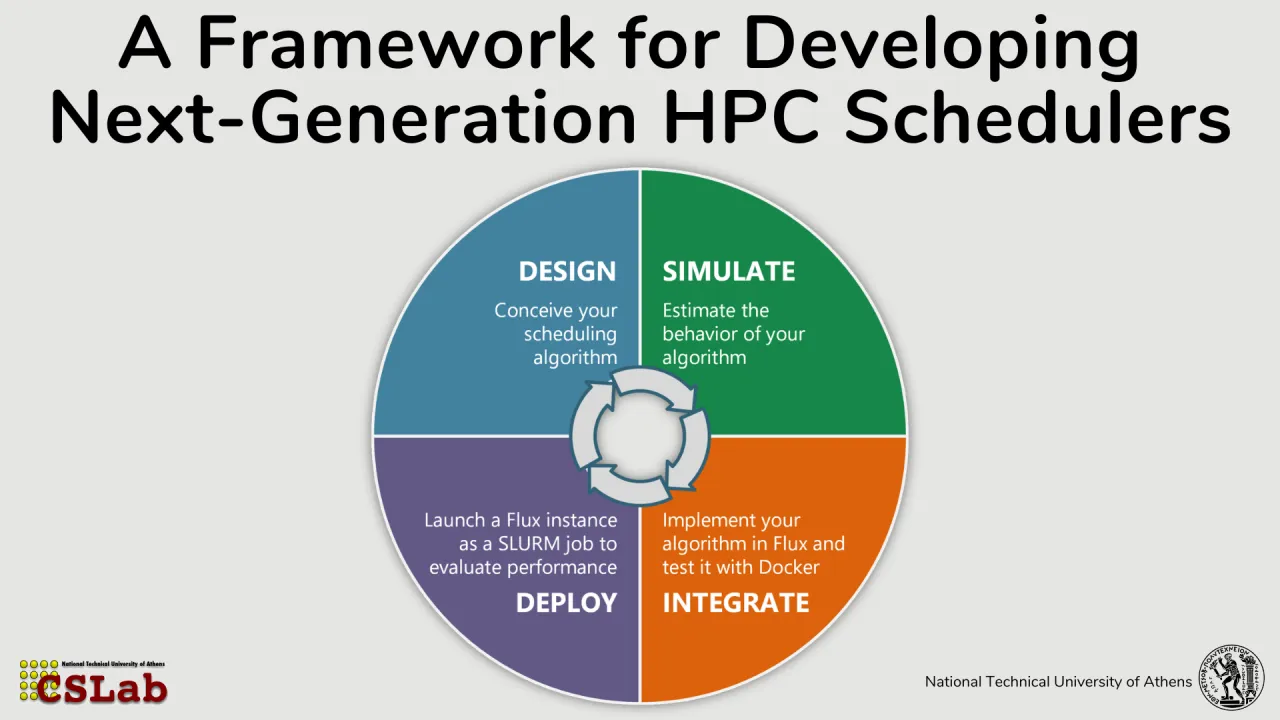
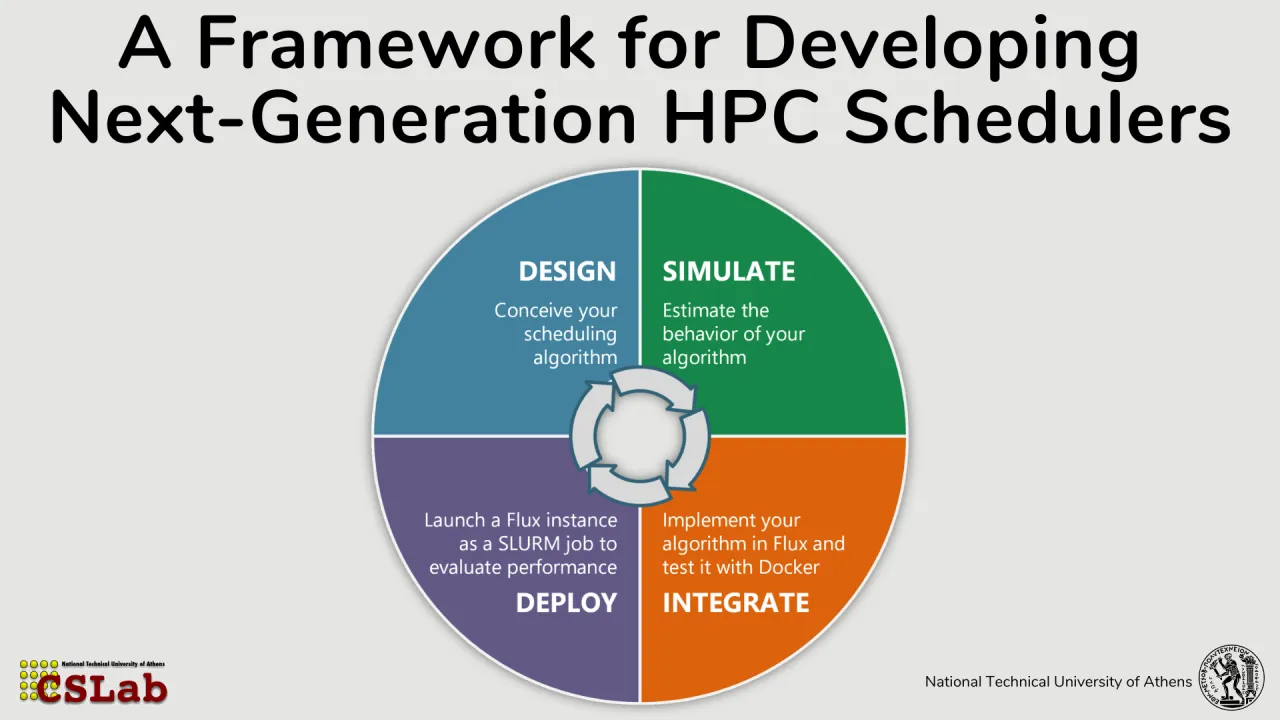
The increasing diversity and scale of high-performance computing (HPC) systems and workloads, ranging from traditional scientific simulations to emerging AI/ML applications, combined with the continued scale-up and scale-out growth in node counts, place growing demands on resource management systems. Modern scheduling strategies must balance multiple, often competing objectives such as throughput, fairness, energy efficiency, and application performance. Advanced techniques including co-scheduling, which enables job co-location on shared resources, and job moldability, where job process counts are determined at scheduling time rather than submission time, offer significant potential benefits. However, validating such scheduling algorithms remains challenging, as researchers typically lack access to dedicated infrastructures with administrative control to deploy production-level resource managers. Furthermore, scheduling experiments are expensive and time-intensive, requiring substantial computational and energy resources, which makes large-scale real-world evaluation impractical and forces experimentation to be highly selective. This work introduces a unified framework for evaluating HPC scheduling algorithms that bridges the gap between simulation and real-system experimentation. The framework integrates ELiSE (Efficient Lightweight Scheduling Estimator), a Python-based scheduling prototyping and simulation environment, with Flurm, a user-space deployment mechanism that nests the Flux resource manager inside standard Slurm allocations. Together, these components enable a closed-loop workflow in which researchers can design, simulate, test, and deploy custom scheduling policies with minimal overhead. ELiSE offers a flexible platform for scheduling algorithm development, supporting high-level abstractions, synthetic and trace-driven workloads, and efficient exploration and evaluation across key performance metrics. Once validated in simulation, algorithms can be implemented inside Flux and then deployed using Flurm. This enables researchers to test their algorithms with real MPI jobs in a production environment while remaining fully isolated from the system-level resource manager and without requiring administrative privileges. Preliminary results demonstrate that Flurm incurs minimal overhead relative to native Slurm execution, making it a reliable proxy for real-world scheduler behavior. Overall, this framework lowers the barrier to entry for HPC scheduling research, accelerates the development and validation of advanced scheduling strategies, and provides a practical, high-fidelity environment for end-to-end evaluation.
Contributors:
The increasing diversity and scale of high-performance computing (HPC) systems and workloads, ranging from traditional scientific simulations to emerging AI/ML applications, combined with the continued scale-up and scale-out growth in node counts, place growing demands on resource management systems. Modern scheduling strategies must balance multiple, often competing objectives such as throughput, fairness, energy efficiency, and application performance. Advanced techniques including co-scheduling, which enables job co-location on shared resources, and job moldability, where job process counts are determined at scheduling time rather than submission time, offer significant potential benefits. However, validating such scheduling algorithms remains challenging, as researchers typically lack access to dedicated infrastructures with administrative control to deploy production-level resource managers. Furthermore, scheduling experiments are expensive and time-intensive, requiring substantial computational and energy resources, which makes large-scale real-world evaluation impractical and forces experimentation to be highly selective. This work introduces a unified framework for evaluating HPC scheduling algorithms that bridges the gap between simulation and real-system experimentation. The framework integrates ELiSE (Efficient Lightweight Scheduling Estimator), a Python-based scheduling prototyping and simulation environment, with Flurm, a user-space deployment mechanism that nests the Flux resource manager inside standard Slurm allocations. Together, these components enable a closed-loop workflow in which researchers can design, simulate, test, and deploy custom scheduling policies with minimal overhead. ELiSE offers a flexible platform for scheduling algorithm development, supporting high-level abstractions, synthetic and trace-driven workloads, and efficient exploration and evaluation across key performance metrics. Once validated in simulation, algorithms can be implemented inside Flux and then deployed using Flurm. This enables researchers to test their algorithms with real MPI jobs in a production environment while remaining fully isolated from the system-level resource manager and without requiring administrative privileges. Preliminary results demonstrate that Flurm incurs minimal overhead relative to native Slurm execution, making it a reliable proxy for real-world scheduler behavior. Overall, this framework lowers the barrier to entry for HPC scheduling research, accelerates the development and validation of advanced scheduling strategies, and provides a practical, high-fidelity environment for end-to-end evaluation.
Contributors:
Format
on-demandon-site


