Turbocharging AI Efficiency: Benchmarking TFLN MZI Photonic Architectures
Tuesday, June 10, 2025 3:00 PM to Thursday, June 12, 2025 4:00 PM · 2 days 1 hr. (Europe/Berlin)
Foyer D-G - 2nd floor
Research Poster
Emerging Computing TechnologiesOptimizing for Energy and Performance
Information
Poster is on display and will be presented at the poster pitch session.
Photonic computing is a promising approach to address the critical power consumption challenges in electronic computing, particularly in artificial intelligence (AI) and machine learning applications, due to its capabilities in parallel computation and high energy-efficiency. One of the most important elements in most photonic architectures is the Mach-Zehnder Interferometer (MZI) which performs multiplication in a very efficient way. Various arrangements of MZIs have been proposed and implemented, but a direct comparison of key metrics such as power efficiency is difficult as the assumptions vary across existing works.
This work presents a rigorous evaluation and comparison of prominent MZI architectures for AI tasks, utilizing the specialized simulation platform CiMLoop and fixed boundary conditions to ensure consistency in evaluation metrics. We focus on three different arrangements of MZIs based on thin-film lithium niobate (TFLN) technology: the independent MZI-array, the singular value decomposition (SVD) MZI-array, and the crossbar-array architectures. TFLN-based MZIs are particularly promising due to their excellent electro-optic properties and potential for high-speed modulation.
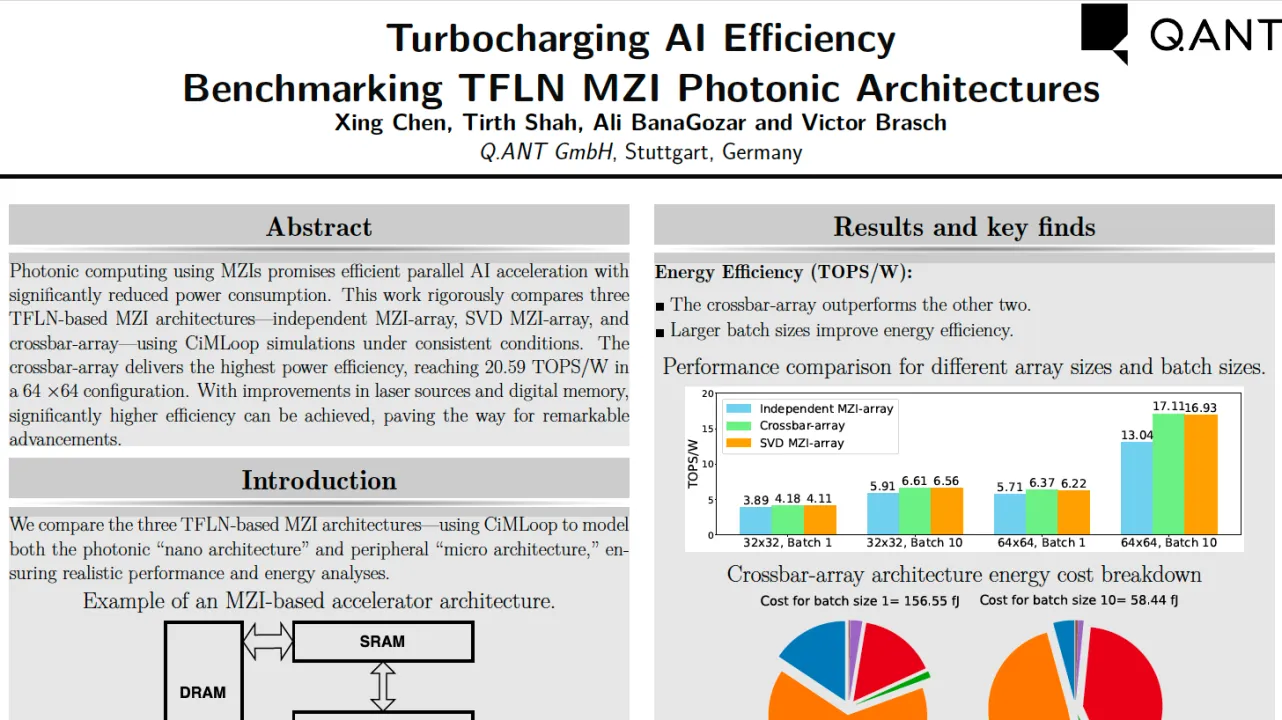
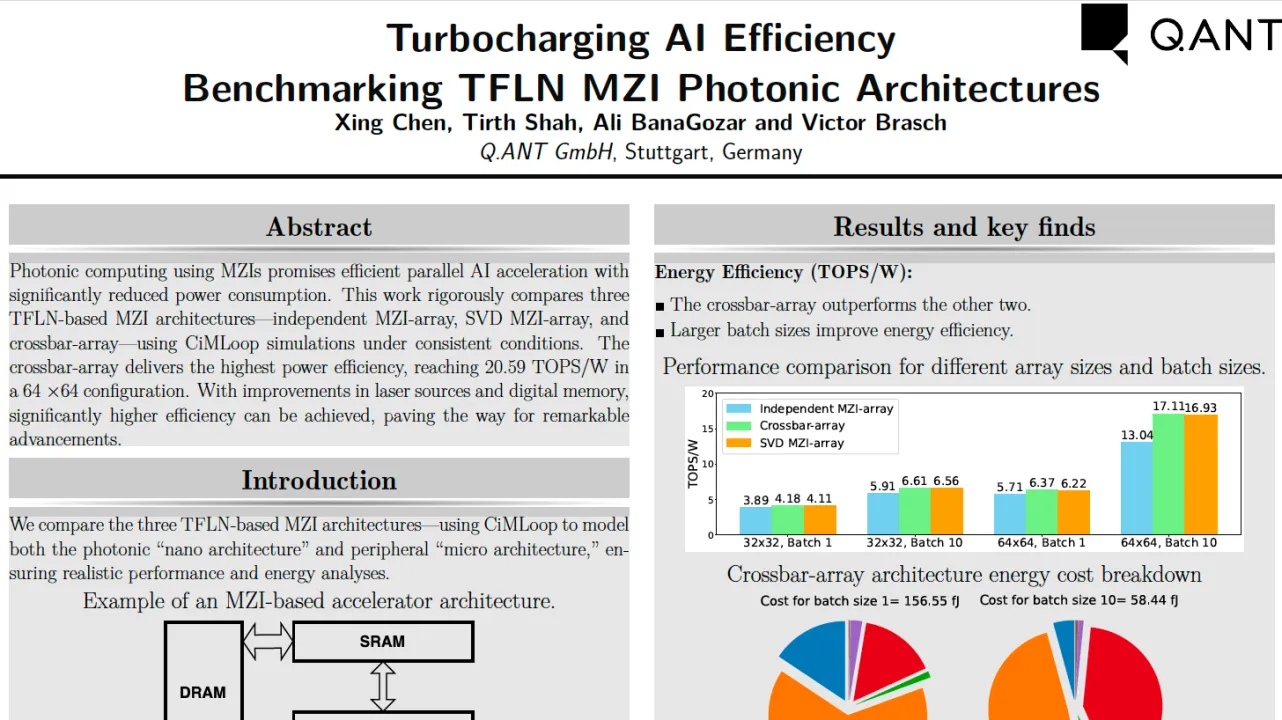
Our simulation results reveal that photonic architectures can substantially surpass today's electronic hardware in performance, with the best photonic configuration achieving 20.59 TOPS/W for a 64×64 crossbar-array. The crossbar-array architecture consistently outperforms both the SVD MZI-array and independent MZI-array designs across all configurations.
Larger array sizes and batch sizes contribute significantly to improved efficiency across all architectures. Furthermore, lasers and digital memories are identified as primary bottlenecks, highlighting critical areas for future development in photonic computing. Motivated by these insights, we propose several ways to increase the performance of photonic hardware architectures, focusing on optimizing laser efficiency and reducing digital memory cost. These improvements can enhance the efficiency of TFLN-based photonic accelerators by another order of magnitude. While these advancements push the boundaries of current MZI array based architectures, other emerging photonic architectures, such as reservoir computing and physical neural networks, are also exciting areas for future exploration, with the potential to unlock even greater computational efficiency.
Contributors:
Photonic computing is a promising approach to address the critical power consumption challenges in electronic computing, particularly in artificial intelligence (AI) and machine learning applications, due to its capabilities in parallel computation and high energy-efficiency. One of the most important elements in most photonic architectures is the Mach-Zehnder Interferometer (MZI) which performs multiplication in a very efficient way. Various arrangements of MZIs have been proposed and implemented, but a direct comparison of key metrics such as power efficiency is difficult as the assumptions vary across existing works.
This work presents a rigorous evaluation and comparison of prominent MZI architectures for AI tasks, utilizing the specialized simulation platform CiMLoop and fixed boundary conditions to ensure consistency in evaluation metrics. We focus on three different arrangements of MZIs based on thin-film lithium niobate (TFLN) technology: the independent MZI-array, the singular value decomposition (SVD) MZI-array, and the crossbar-array architectures. TFLN-based MZIs are particularly promising due to their excellent electro-optic properties and potential for high-speed modulation.
Our simulation results reveal that photonic architectures can substantially surpass today's electronic hardware in performance, with the best photonic configuration achieving 20.59 TOPS/W for a 64×64 crossbar-array. The crossbar-array architecture consistently outperforms both the SVD MZI-array and independent MZI-array designs across all configurations.
Larger array sizes and batch sizes contribute significantly to improved efficiency across all architectures. Furthermore, lasers and digital memories are identified as primary bottlenecks, highlighting critical areas for future development in photonic computing. Motivated by these insights, we propose several ways to increase the performance of photonic hardware architectures, focusing on optimizing laser efficiency and reducing digital memory cost. These improvements can enhance the efficiency of TFLN-based photonic accelerators by another order of magnitude. While these advancements push the boundaries of current MZI array based architectures, other emerging photonic architectures, such as reservoir computing and physical neural networks, are also exciting areas for future exploration, with the potential to unlock even greater computational efficiency.
Contributors:
Format
On DemandOn Site
