Design and Implementation of MPI Collective Operations for Large Message Communication on AMD GPUs
Tuesday, June 10, 2025 3:00 PM to Thursday, June 12, 2025 4:00 PM · 2 days 1 hr. (Europe/Berlin)
Foyer D-G - 2nd floor
Research Poster
Heterogeneous System ArchitecturesInterconnects and NetworksRuntime Systems for HPC
Information
Poster is on display and will be presented at the poster pitch session.
Modern high-performance computing (HPC) systems are increasingly reliant on GPUs, especially for scientific and machine learning tasks. Traditionally, NVIDIA GPUs dominated the space with CUDA support, but the emergence of AMD GPUs in next-generation exascale systems like El Capitan and Frontier has created a growing need for optimized software solutions. As of November 2024, El Capitan and Frontier rank first and second on the TOP500 list, featuring AMD MI300A and MI300X GPUs, underscoring the demand for efficient MPI collective communication operations to fully exploit the potential of such highly capable heterogeneous systems.
Many applications, especially in deep learning (DL) and HPC, depend on MPI collectives for efficient communication across GPUs and nodes. DL applications require operations like Allreduce, Allgather, and Alltoall to aggregate gradients and synchronize training data across GPUs, often involving large message sizes from megabytes to gigabytes. Similarly, HPC applications like heFFTe and AWP-ODC rely on Alltoall for large-scale message communication. Efficient implementation of MPI collectives is crucial for optimizing performance in such data-heavy workloads.
While current GPU-aware communication optimizations have focused on NVIDIA GPUs, AMD's growing presence in exascale systems necessitates new strategies. Existing methods, such as GPU reduction kernels and collective-compression designs, are insufficient for AMD's Slingshot interconnects and diverse network topologies. Additionally, approaches using CPU staging buffers fail to take full advantage of GPU-Direct MPI capabilities, resulting in performance inefficiencies.
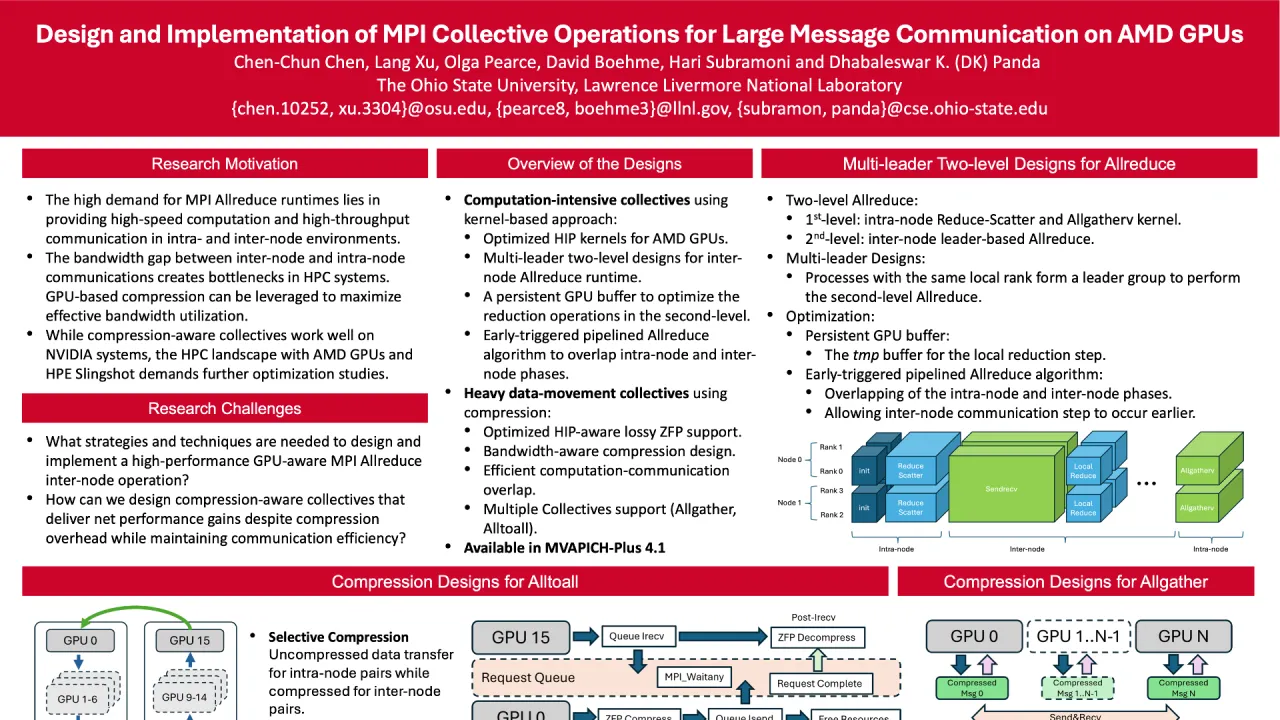
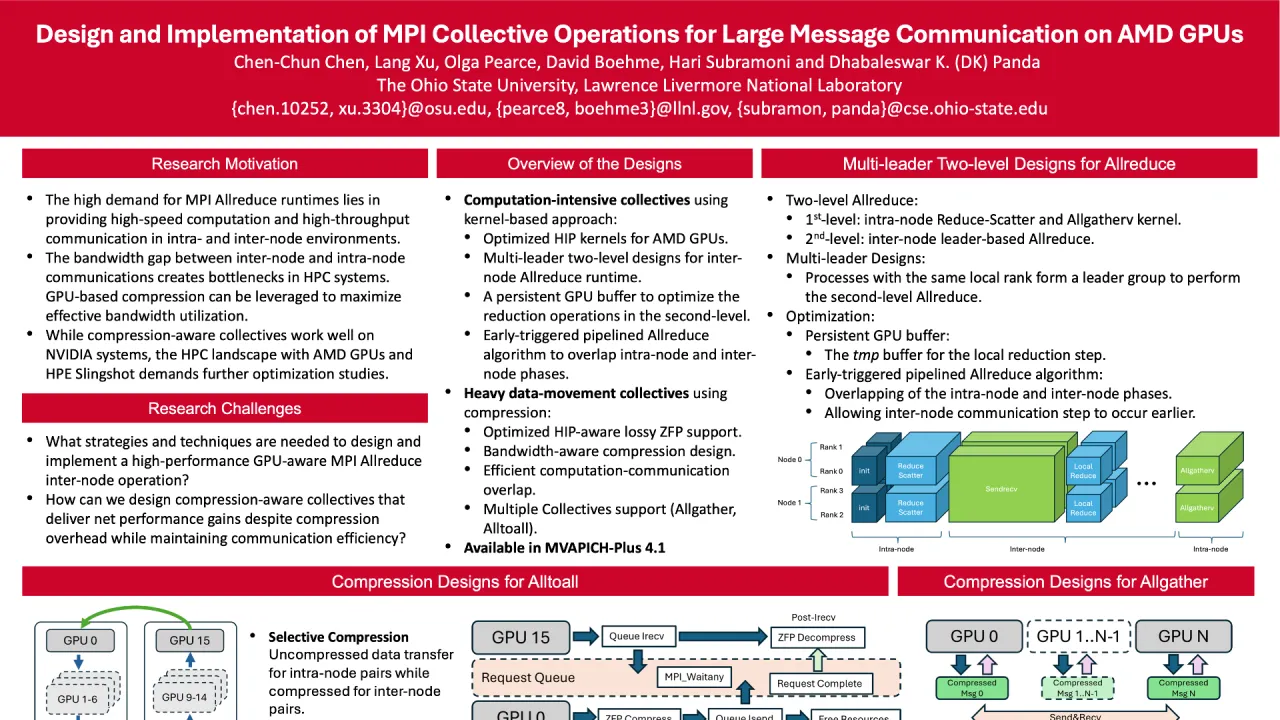
To address these challenges, we propose kernel-based multi-leader two-level designs for Allreduce and employ compression techniques to optimize data-heavy collectives like Alltoall and Allgather. Our HIP-based reduction kernels for AMD GPUs handle both intra-node Allreduce and two-level inter-node Reduce-Scatter and Allgatherv operations. We introduce persistent GPU buffers to optimize second-level Allreduce algorithms, and implement an early-triggered pipeline to enhance overlap between intra- and inter-node phases. This approach reduces the inefficiencies of CPU-based Allreduce methods.
For compression-aware collectives, we use GPU-aware MPI to operate directly on GPU buffers, eliminating CPU staging. Our Alltoall design prevents deadlocks with a ring-like structure, using non-blocking MPI operations combined with asynchronous ZFP compression and decompression. Optimizing for self-communication scenarios, we utilize local GPU copies, reducing unnecessary overhead. Our Allgather implementation compresses data once per process, circulating it through a ring structure, simplifying buffer management and improving performance.
We evaluated our designs on Frontier at the Oak Ridge Leadership Computing Facility, equipped with 4 AMD MI250X GPUs per node, and AMD EPYC 7A53 processors with 512 GB DDR4 memory. Benchmark tests show significant performance improvements in collective operations, with our Allreduce implementation achieving up to 4.26x speedup over RCCL. Compression-aware Alltoall and Allgather designs similarly exhibit strong performance, with speedups of up to 13.46x and 7.15x respectively, demonstrating the effectiveness of our approach in optimizing MPI collectives on AMD GPUs.
Contributors:
Modern high-performance computing (HPC) systems are increasingly reliant on GPUs, especially for scientific and machine learning tasks. Traditionally, NVIDIA GPUs dominated the space with CUDA support, but the emergence of AMD GPUs in next-generation exascale systems like El Capitan and Frontier has created a growing need for optimized software solutions. As of November 2024, El Capitan and Frontier rank first and second on the TOP500 list, featuring AMD MI300A and MI300X GPUs, underscoring the demand for efficient MPI collective communication operations to fully exploit the potential of such highly capable heterogeneous systems.
Many applications, especially in deep learning (DL) and HPC, depend on MPI collectives for efficient communication across GPUs and nodes. DL applications require operations like Allreduce, Allgather, and Alltoall to aggregate gradients and synchronize training data across GPUs, often involving large message sizes from megabytes to gigabytes. Similarly, HPC applications like heFFTe and AWP-ODC rely on Alltoall for large-scale message communication. Efficient implementation of MPI collectives is crucial for optimizing performance in such data-heavy workloads.
While current GPU-aware communication optimizations have focused on NVIDIA GPUs, AMD's growing presence in exascale systems necessitates new strategies. Existing methods, such as GPU reduction kernels and collective-compression designs, are insufficient for AMD's Slingshot interconnects and diverse network topologies. Additionally, approaches using CPU staging buffers fail to take full advantage of GPU-Direct MPI capabilities, resulting in performance inefficiencies.
To address these challenges, we propose kernel-based multi-leader two-level designs for Allreduce and employ compression techniques to optimize data-heavy collectives like Alltoall and Allgather. Our HIP-based reduction kernels for AMD GPUs handle both intra-node Allreduce and two-level inter-node Reduce-Scatter and Allgatherv operations. We introduce persistent GPU buffers to optimize second-level Allreduce algorithms, and implement an early-triggered pipeline to enhance overlap between intra- and inter-node phases. This approach reduces the inefficiencies of CPU-based Allreduce methods.
For compression-aware collectives, we use GPU-aware MPI to operate directly on GPU buffers, eliminating CPU staging. Our Alltoall design prevents deadlocks with a ring-like structure, using non-blocking MPI operations combined with asynchronous ZFP compression and decompression. Optimizing for self-communication scenarios, we utilize local GPU copies, reducing unnecessary overhead. Our Allgather implementation compresses data once per process, circulating it through a ring structure, simplifying buffer management and improving performance.
We evaluated our designs on Frontier at the Oak Ridge Leadership Computing Facility, equipped with 4 AMD MI250X GPUs per node, and AMD EPYC 7A53 processors with 512 GB DDR4 memory. Benchmark tests show significant performance improvements in collective operations, with our Allreduce implementation achieving up to 4.26x speedup over RCCL. Compression-aware Alltoall and Allgather designs similarly exhibit strong performance, with speedups of up to 13.46x and 7.15x respectively, demonstrating the effectiveness of our approach in optimizing MPI collectives on AMD GPUs.
Contributors:
Format
On DemandOn Site


